ENG 612/MLL 772 Topics in DH: Humanities Data Spring 2022
Lab 5 - Python and Jupyter Notebooks
To access the notebook we are using for today’s lab, follow the first link below. Loading the notebook may take a few minutes; this is normal. The second link is for the lab’s GitHub repository.
Acknowledgments
I have drawn from Melanie Walsh’s Introduction to Cultural Analytics & Python online textbook in creating this lab.
Python, Jupyter, and Binder
In today’s lab, we are going to be exploring programming in a humanities research context using Python. To do this, we will be working with Jupyter, or a “Jupyter notebook” (.ipynb file). Jupyter is a web-based platform for creating and sharing “computational documents,” or documents that mix words with executable code. You don’t need to download anything to participate in today’s lab. Instead, I’ve used Binder to make the notebook we will be using available and runnable online. We’ll be interacting with our lab 5 notebook in the JupyterLab interface.
While it’s possible to run Python scripts (saved in a .py file) from your command line, using Jupyter notebooks is a popular way to conduct data analysis because Jupyter notebooks combine executable code, explanatory text, and data visualizations, which makes them great for teaching and learning. By running a cell of Python code in a Jupyter notebook, you don’t need to interact with the command line, and you can break your code up into discrete steps or sections more easily, which helps to understand what each part of your code does. Jupyter notebooks are also a great way to save code and share it with others, as you can document in the notebook itself through explanatory text what your code is doing. See “The Life of a Python Script” section of Chapter 2 in Walsh’s textbook for more information about Jupyter notebooks and running Python scrips from the command line, and see the “Install Python & JupyterLab” and the “How to Use Jupyter Notebooks” for more information about how to run Jupyter locally on your own machine if you are interested.
Why Are We Doing This?
This lab is not about teaching you programming: that would require a whole course in of itself. Instead, we are going to focus on developing some literacy in what coding looks like in a humanities research context, and, perhaps even more importantly, on understanding how and why one would ever want to learn anything about coding in the first place. Coding in an academic context is a research skill; it is not magic, it does not take special smarts or a degree in computer science, and it is not only for “technical people.” It does, however, take time and perseverance to learn (especially the first time you try to learn a programming language – it gets a bit easier as you learn more), and it’s not necessarily that “fun” to learn for its own sake, in my opinion. As Quinn Dombrowski writes in “DSC #D12”, although at first trying to use a programming language you are learning “sucks,” “you can only get there by practicing. And you’ll only practice if it’s worth it. And it’s only worth it if it’s the only way you, as a humanist, can do the things you want to do.” It may be helpful to keep that in mind during today’s lab. Doing programming for the first time basically “sucks,” but it does get better with practice.
So what can you do if you know a bit of programming that you can’t do otherwise? The answer is “a lot,” but it may be helpful to contextualize that answer a bit. Last week we spent some time exploring Voyant. As we saw, it is a powerful tool for text analysis that includes a sophisticated array of methods, tools, and visualizations. Yet, we as users of that system are limited to the methods, tools, and visualizations that the designers of Voyant have made available to us (which, again, is a lot but certainly not everything that it is possible to do with text). We are also limited to the parameters they have set for each tool and the decisions they have made about how each tool will work. For example, while it’s possible to use Voyant to do topic modeling, Voyant implements only one specific kind of topic modeling (there are several different kinds). While this likely isn’t a problem for the more casual user, such as a student in a class, it could be a problem for a researcher. And finally, we are limited by the fact that Voyant is a web-based tool that doesn’t handle large datasets very well. If we have lots of data that we want to perform text analysis on, we will run into trouble with Voyant pretty quickly.
None of the above is a critique of Voyant; rather, it’s an explanation of why taking the time to learn programming might be worth it if you want to work with humanities data. If you learn how to do some programming in Python, for example, you can do everything you can do with Voyant (and more), but in the specific way that fits your particular research questions, that produces the specific outputs and visualizations you want, and that allows you to analyze a lot more data. As we’ve seen over the past few weeks of this course, there is a lot you can do with out-of-the-box tools, and for many tasks, they may be all you need. But, as Roopika Risam writes in “DSC #D12”, if you learn to code, you “have choices” that you do not have when you use out-of-the-box tools.
“Wait But I Do Want to Learn to Code!”
Ok, great! I strongly recommend Melanie Walsh’s free online textbook, Introduction to Cultural Analytics & Python. It is written for people interested in the humanities and social sciences who want to learn Python but who don’t know anything about coding. It assumes no prior knowledge and it includes lots of humanities research-specific examples and skills, including chapters on web scraping and data collection, text analysis, network analysis, and mapping. You may also want to look into registering for a course at DHSI (there are several that focus on programming, and they do offer scholarships, though it’s a bit unclear at the moment what is happening with scholarships this year specifically). There are also various courses, boot camps, and workshops about learning to code offered at UM, though these are less likely to be about learning to code in a humanities research context.
No matter how you go about learning to code, the main thing to remember is that you can absolutely learn to do it. Find a context for learning that works for you (whether a course, a study group, working your way independently through a textbook, etc.) and stick to it. You will not become an expert after completing one workshop or one course or the exercises in one textbook, but the good news is that you don’t need to be an expert in programming to begin to use it to advance your research.
How I Learned to Code
I do not have formal training in programming or data management; instead, I learned everything I know because I wanted or needed to do it for a job or for my research. In other words, I learned things “on the job” and usually within the specific context of needing to do something to move a particular project forward. I also learned things slowly, over a number of years. I started with web-based stuff: HTML and CSS, mainly (this was to earn extra money when I was getting my MA). Then I learned MySQL (database management and querying) and regular expressions when working as a research assistant for a DH project while getting my PhD (and I used those skills to create a small experimental DH project of my own). I also began learning R at this time (this was also connected to the research assistantship). After I graduated and got a job, I learned a lot more about R when participating in the earlier stages of the WhatEvery1Says project; I volunteered to do something for the project that required me to learn a fair amount about R, though I was still only merely proficient at the end of that work. As the project went on, we switched over entirely to Python, so I started learning that so that I could help more with the technical aspects of the project (there was a lot to do). I learned it in bits and pieces until, in fall 2018, I organized a small group of fellow project participants to work through Folgert Karsdorp’s “Python Programming for the Humanities” together, completing one chapter every one to two weeks. We got through most of the chapters in about a semester, and then I had the skills to start doing a lot of programming for the project, which, in turn, helped me to learn even more.
I’ve been working steadily in Python for a few years now, but I am merely an average coder, if that. My code is usually rather “hacky” – meaning inelegant and pieced together in various ways – because if I am faced with a coding problem I don’t know how to solve, I’ll just google it and copy other people’s approaches until I get it to work. My code is messy and I am generally uninterested in finding the computationally fastest or most efficient ways to do things (unless I have to because I am working with large datasets), I still don’t know all of the Python syntax or rules by heart, and I’m constantly forgetting how to do things. This is all fine with me, because my basic approach to programming is “do what works.” I use programming to help me with some of my research, and that’s enough for me.
Research Context of Today’s Lab
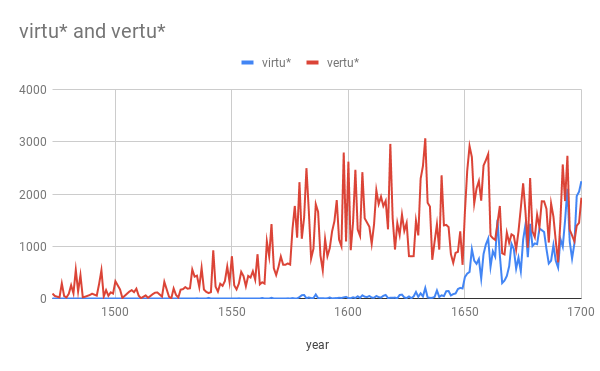
I wrote the code we are going to be working with in today’s lab to help answer a specific question Jessica Rosenberg had about the spelling of the word “virtue” in early modern texts. She knew from her general knowledge of the period that, prior to around 1700, the word in English was commonly spelled with an “e” — “vertue” – rather than with an i – “virtue.” This is significant because while scholars in Renaissance studies have long discussed the Latinate etymology of the word (virtus, meaning “manliness,” “virility,” and “virtue”) and its association with masculinity, its spelling with an “e” reveals a French etymology (vertu) and an association with words like “verdant.” Jessica wanted to quantify this observation and thus make it more precise: specifically, she wanted to know how much more common the spelling “vertue” was than the spelling “virtue” in English early modern texts prior to about 1700. This question is connected to larger arguments she makes in her book about how early modern print culture was suffused with a botanical idiom.
To answer this question, we downloaded the available corpus of EEBO (Early English Books Online) Phase I and Phase II texts (click on the link to learn more about what that means). This came to about 61,300 texts at the time (about 2.5 years ago). This is, of course, not the entirety of everything that exists in English from the period – far from it. But it is the most comprehensive dataset of plain-text texts from the period available. The texts in this dataset are encoded using TEI, a flavor of XML. You can look at a sample text here. I’ve also included a zip file of the EEBO-TCP data we used in our Lab5 Google drive folder if you want to check it out for yourself (the zip file is over 2 GB when compressed and over 8.5 GB when uncompressed, so it will take time to download and you will want to make sure you can easily store that amount of data on your machine). You can also now download Phase I and Phase II texts from this page; again, the texts available for download now may differ slightly than the collections we used 2.5 years ago.
I then wrote a Python script that opened up each individual file (each file is 1 text) and searched through its content for various forms of the word “virtue” spelled with an “e” or an “i” (e.g., “virtue”/”vertue,” “virtuous”/”vertuous”, “virtuositie”/”vertuositie”, etc.). If the script found a file including any of these words, it saved information about the text (filename, author, title, and year of publication) and the number of times words spelled with "vertu*" appeared in the text vs. the number of times words spelled with "virtu*" appeared in the text to a .csv file. You can see the resulting spreadsheet in our Lab5 Google drive folder (“vir-ver-counts-specific”). Using this information, we were able to determine the number of texts in EEBO’s collection containing variations of "vertu*" published each year vs the number of texts containing variations of "virtu*" published each year (we did this using simple formulas available in Google sheets; to examine these formulas, see the “counts-by-year” tab and click on values in column B and C; near the top of the screen, in the formulas bar, you will see the formulas we used). We found that ~99% of texts in EEBO published before 1600 used variations of "vertu*" and ~97% of texts in EEBO published before 1650 used variations of "vertu*". It isn’t until after 1650, as we can see in the below chart (from the “counts-by-year” tab in the spreadsheet included in the Lab5 Google drive folder), that variations of "virtu*" started to become more common.
Ok, Finally, Let’s Look at the Code
Open up the Jupyter notebook we are using for this lab using the first link below (loading may take up to a few minutes; this is normal). The second link is to the lab’s GitHub repository.
The lab 5 notebook only explains the aspects of Python syntax that you will need to complete this lab. For a much fuller introduction to Python basics such as variables, data types, etc., see Walsh’s textbook.
Lab Notebook Entry
Due:
- By class on Wed, March 2
In your lab notebook entry for this week, you should include the following things:
- Short responses to questions 1-4 from the Lab 5 Jupyter notebook.
- A response to the following prompt: Discuss your experience exploring Python in this week’s lab in relation to at least one of our readings assigned for this week (week 6). This discussion should be specific but it needn’t be long (i.e., 2-4 paragraphs).
- The dataset you plan to use in completing Lab 6. This means you should read through the Lab 6 assignment page before you make your selection. Please include a link to the dataset and/or information about it.